
Le projet MÉTOPES – Méthodes et outils pour l’édition structurée – vise à mettre au point, à développer et diffuser, librement dans la sphère publique, par des actions de formation auprès des éditeurs publics et des revues labellisées CNRS un ensemble d’outils et de méthodes leur permettant d’organiser leur production et leur diffusion papier et numérique sur le modèle du Single Source Publishing.
Principes
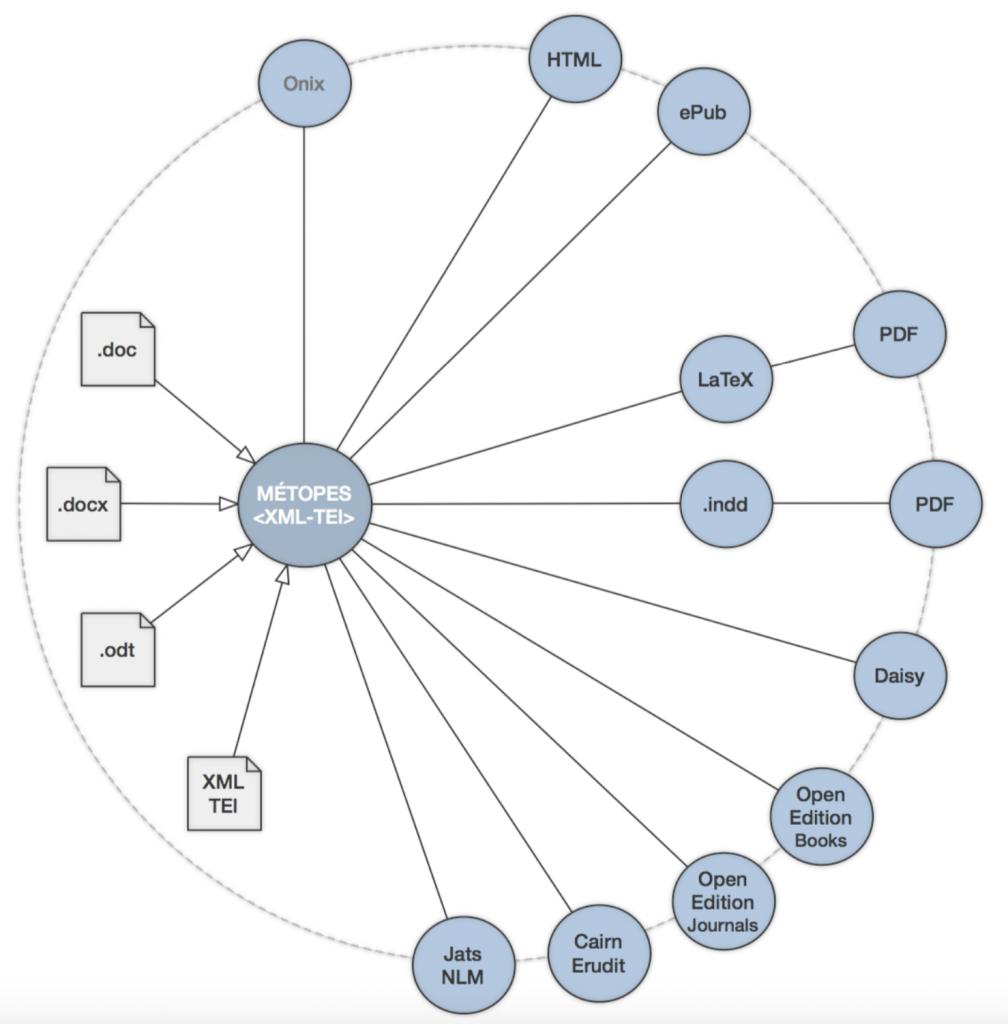
Le projet MÉTOPES « Méthodes et outils pour l’édition structurée »[1] vise à mettre au point, à développer et diffuser, librement dans la sphère publique, par des actions de formation auprès des éditeurs publics et des revues labellisées CNRS un ensemble d’outils et de méthodes leur permettant d’organiser leur production et leur diffusion papier et numérique dans un environnement normé à fort potentiel d’interopérabilité sur le modèle du Single Source Publishing[2]. Un des apports principaux est de rationaliser et de factoriser, au sein de la communauté des éditeurs universitaires et de recherche publics, le travail éditorial tout en favorisant la mise en place de stratégies de diffusion multisupports, en assurant une pérennisation des contenus et une haute qualité des métadonnées associées.
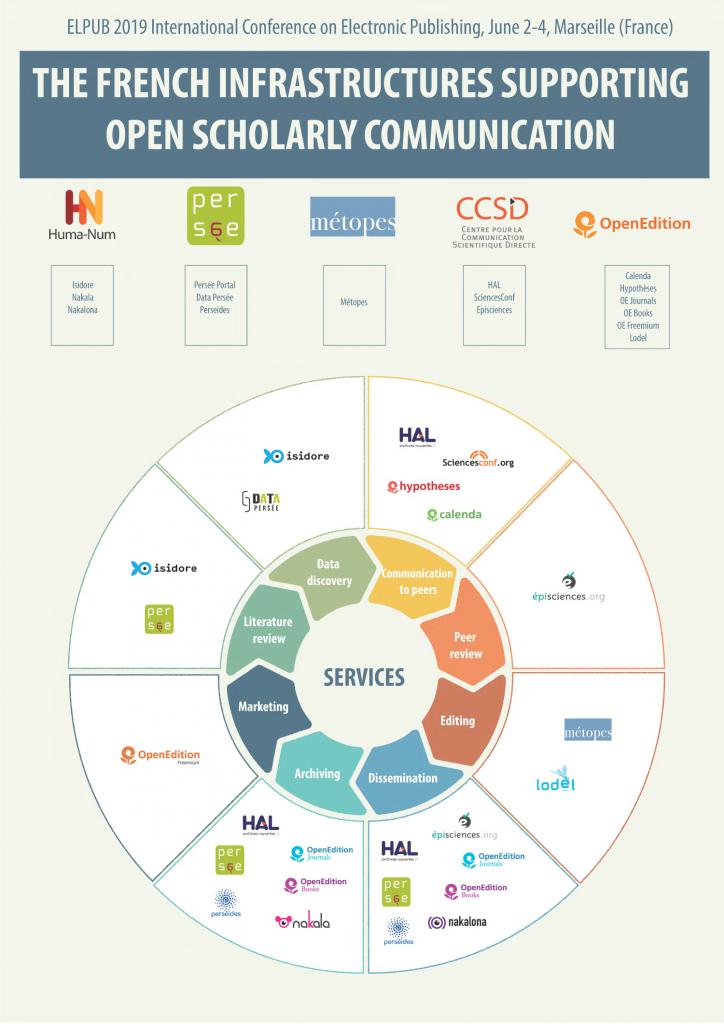
Ce projet, principalement orienté vers la production des contenus, est fortement articulé, par le biais de la prise en compte de la norme ONIX et de ses exploitations, aux travaux et développements menés parallèlement par OpenEdition (USR 2004 du CNRS, Marseille). L’ensemble des deux dispositifs permet de développer conjointement un réservoir de contenus normés (XML-TEI), à haute valeur éditoriale ajoutée (évalués, éditorialisés, structurés…), et un système de catalogage et d’exposition (diffusion) ouvrant vers la possibilité du déploiement d’un catalogue commun (ONIX) des éditeurs publics associés (métadonnées et contenus). Après avoir constitué la partie recherche développement de l’infrastructure nationale de recherche NUMEDIF[3], le projet est devenu en 2018 infrastructure de recherche à part entière (Université de Caen Normandie – CNRS) sous le nom d’IR METOPES. Celle-ci fonctionne en synergie avec les trois autres infrastructures nationales dédiées à l’IST : OpenEdition, Collex-Persée et HAL.
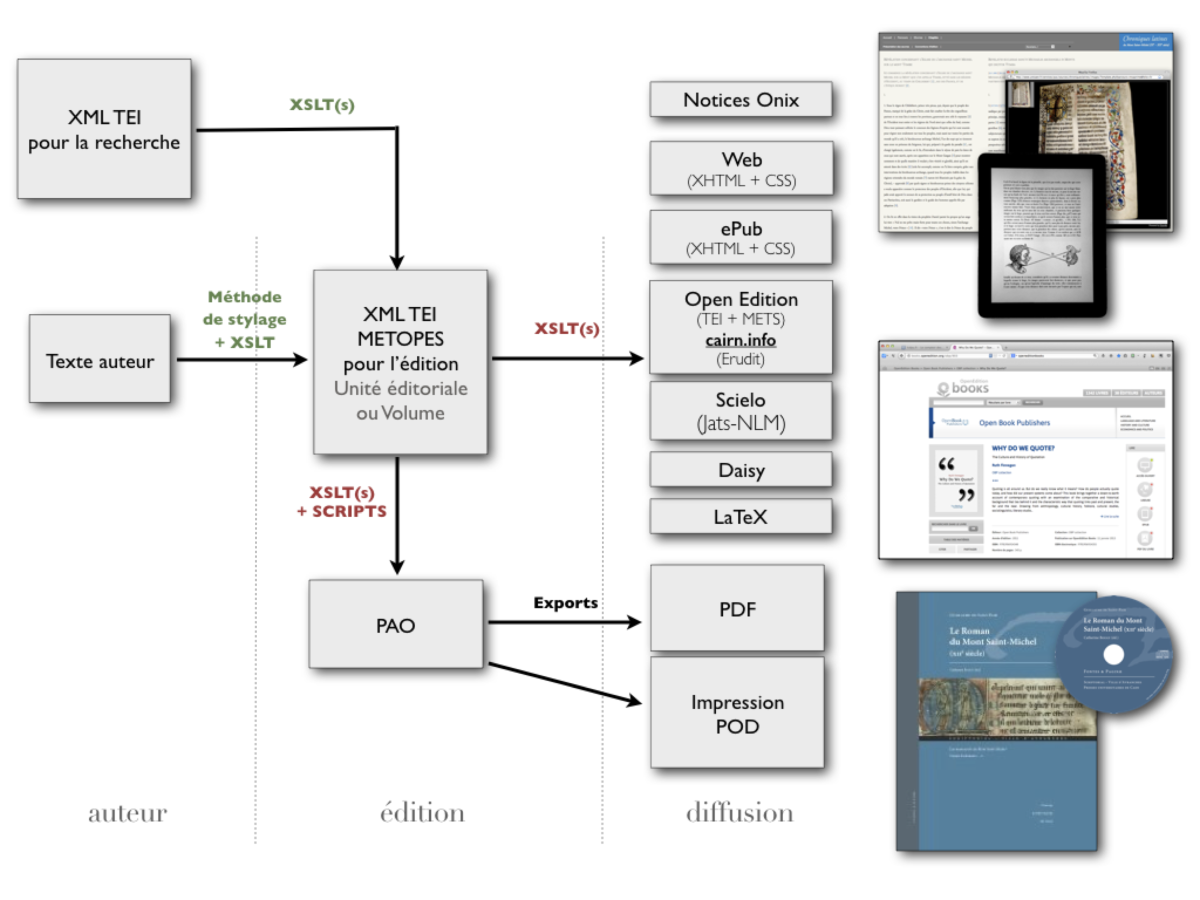
Depuis septembre 2013, le même modèle de données[4] régit les productions d’OpenEdition — ouvrages et périodiques — et des utilisateurs de la chaîne avec des conséquences positives directes quant à l’économie de diffusion des contenus. Une de ces conséquences, et non la moindre, est la suppression des frais de transformation des fichiers pour leur diffusion sur les plateformes[5] mais surtout, assurant à l’éditeur la pleine propriété de fichiers structurés. Ces derniers, fruits d’un travail éditorial unique, sont pérennes, reconfigurables, garants du fond et porteurs de formes de diffusion multiples. Ils remplissent toutes les conditions de l’interopérabilité des fonds soit la possibilité du développement d’un catalogue commun et la mise en œuvre d’un réservoir de publications « qui chuchotent entre elles »[6]. Ils jettent ainsi les bases d’une édition en réseau, miroir d’une érudition qui se conçoit et se construit aujourd’hui en réseau elle aussi…
Ce modèle et les outils d’informatique éditoriale qui l’accompagnent permettent, à partir d’une source unique, de produire toutes les formes de diffusion et est d’ores et déjà compatible avec les schémas nécessaires pour les revues des plateformes OpenEdition Journals, Cairn.info et pour les livres diffusés sur OpenEdition Books.


production d’unités éditoriales (chapitre, article) et de volumes (livre, numéro de revue)
Ce modèle technique et organisationnel entre fortement en résonance avec les réalités, les demandes et les contraintes du contexte aujourd’hui incontournables de la production et de la diffusion numériques. En effet, et en termes d’interopérabilité et d’économie de diffusion des savoirs :
- il repose sur des normes ou sur des standards partagés par de nombreux acteurs du domaine, ce qui est un facteur d’interopérabilité des contenus ;
- il participe à la clarification de la notion de « plus-value éditoriale » en permettant de l’identifier et de la localiser précisément ;
- il est facteur d’économies, ne serait-ce que parce qu’une intervention éditoriale unique permet une multiplicité de formes de diffusion ;
- il est indépendant des modèles économiques : l’éditeur a une totale liberté de choix des articulations formes / modèles de diffusion gratuite ou payante et peut construire des complémentarités entre formes de diffusion ;
- il offre des perspectives nouvelles en termes de droits, à partir de la clarification des statuts du texte et de la claire localisation des acteurs de la plus-value éditoriale. Il permet au couple auteur-éditeur institutionnel de disposer, dans le respect des droits d’auteur, d’une structure riche à partir de laquelle peuvent être produites des formes appauvries pour leur stricte diffusion. Ces aspects peuvent permettre de mettre en place les adaptations les plus pertinentes dans un contexte où peut peser (et ou va peser) le devoir de diffusion en Open Access ;
- il est aussi un point de convergence en termes d’articulation avec les autres métiers de la « vie » du flux numérique (bibliothécaires, archivistes, chercheurs-auteurs, chercheurs-lecteurs…) et, plus encore, en termes d’ouverture aux données de la recherche (textes appareillés et éditions issues de corpus, thèses en ligne…) ;
- il est enfin garant d’une certaine pérennité des données. En effet, l’utilisation d’Unicode et la normalisation documentée des structures (XML-TEI) rend les fichiers produits susceptibles d’un archivage effectué par le Centre informatique National de l’Enseignement supérieur (CiNEs).
Incidences et enjeux éditoriaux
Le poids de la norme et de l’adoption de normes communes et tout au moins interopérables est ici crucial. Il s’agit, schématiquement, d’Unicode pour l’encodage des caractères, du XML pour la description des structures et du choix de la TEI (Text Encoding Initiative) pour la sémantisation[7]. Les années 1990 finissantes ont en effet vu l’apparition de normes et de standards propres à favoriser une certaine stabilité des productions numériques et à permettre l’interopérabilité : stabilisation des encodages à l’échelle du caractère avec la norme Unicode qui rend possible l’échange généralisé des textes ; stabilisation des modes de représentation de l’architecture des contenus avec, parallèlement à l’extension du Web, l’omniprésence du XML et des techniques associées, XSL et CSS ; stabilisation ou plutôt définition de vocabulaires partagés par des communautés et concernant soit les contenus (TEI), soit les produits, leur catalogage (référencement) et leur(s) diffusion(s) (Dublin Core, ONIX).
Cet ensemble permet de généraliser le principe de la dissociation du fond et de la forme et, plus avant, des formes puisque l’un des enjeux est bien l’horizon d’une édition multisupports, voire multimodale.
L’enjeu sous-jacent à la mise en œuvre de ce modèle et de ces techniques ne peut être réduit à un ensemble de dispositifs informatiques ou aux seuls nouveaux protocoles de travail. Il s’agit bien de passer d’une édition numérique centrée sur les outils à une édition numérique centrée sur les données, avec pour objectifs la construction – politique et matérielle – et la pérennisation de fonds inscrits dans un paysage technique numérique non plus subi mais maîtrisé et asservi aux politiques éditoriales publiques.
Déploiement, formations
Avec le soutien d’abord de l’AEDRES puis, depuis 2013, avec la prise en charge intégrale des coûts de développement et de formation par BSN, plus de 100 structures d’édition publique universitaire et de recherche (presses d’université, secrétariats d’édition de revues, presses des écoles françaises à l’étranger, presses d’IFRE…) et plus de 500 personnes (responsables éditoriaux, secrétaires d’édition, de rédaction, maquettistes, graphistes…) ont été formées aux méthodes d’édition structurée par des personnels des Presses universitaires de Caen et du Pôle document numérique. Chaque formation, d’une durée de trois journées, s’effectue sur site et au plus près des préoccupations éditoriales des personnels concernés et s’organise autour de la mise à disposition gratuite et de l’installation des outils dans le service. Ces formations sur site sont combinées avec la tenue d’ateliers thématiques organisés dans le cadre de réseaux : MEDICI (formation de secrétaires de rédaction de revues, formation de formateurs-référents aux outils d’édition structurée XML-TEI), Consortiums Corpus (MASA, CAHIER), Repères, ANF, AEUP (Operas), etc.
Un suivi des utilisateurs et un service de soutien technique sont assurés par deux ingénieurs d’études CNRS du Pôle document numérique en liaison avec OpenEdition.
La diffusion de la chaîne à l’étranger est, par ailleurs, assurée dans le cadre d’accords entre l’AEDRES et ses correspondants : REUN (Argentine), ASEUC (Colombie), LusOpenEdition (Portugal), AEUP (Association of European University Presses)…
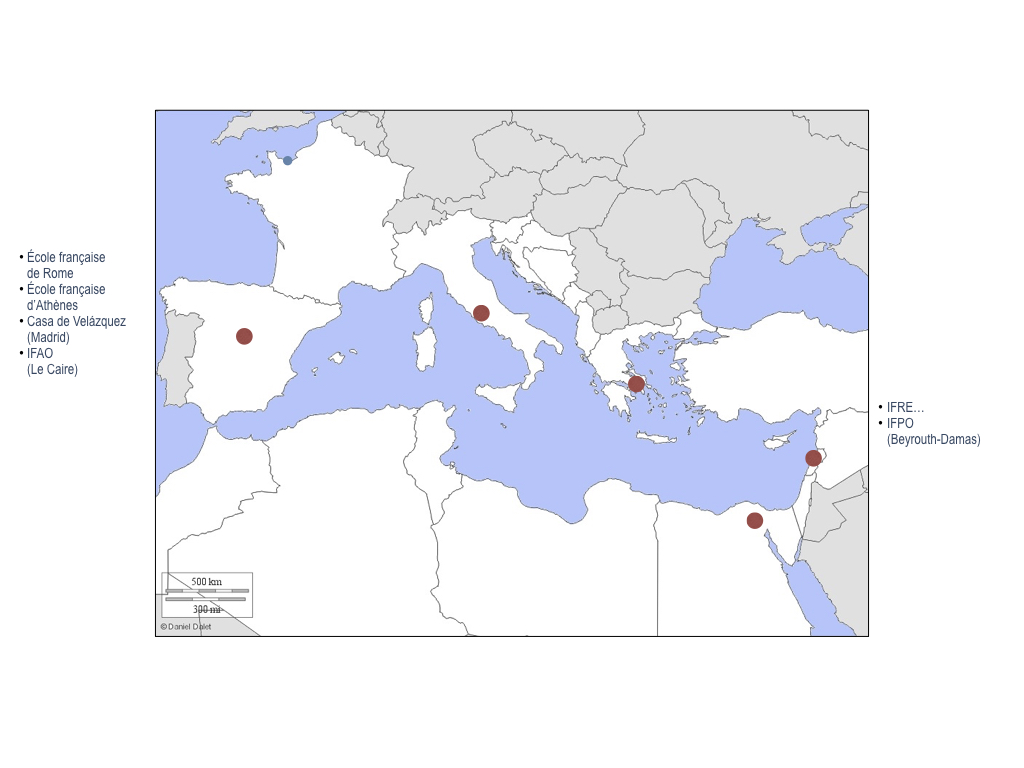
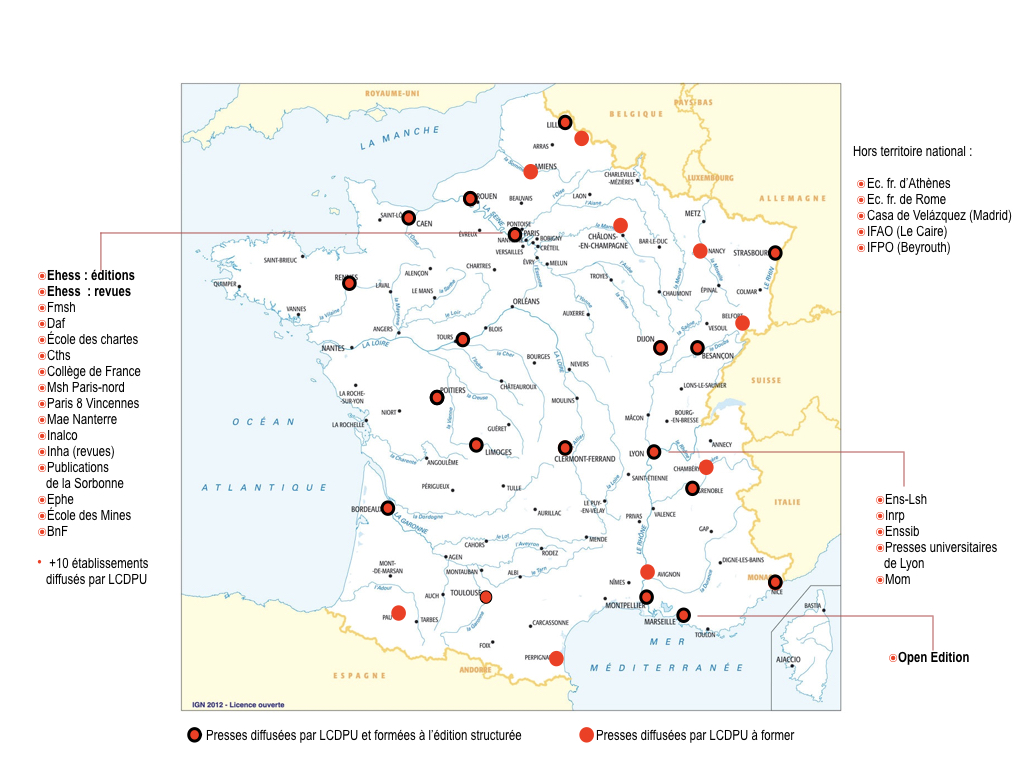
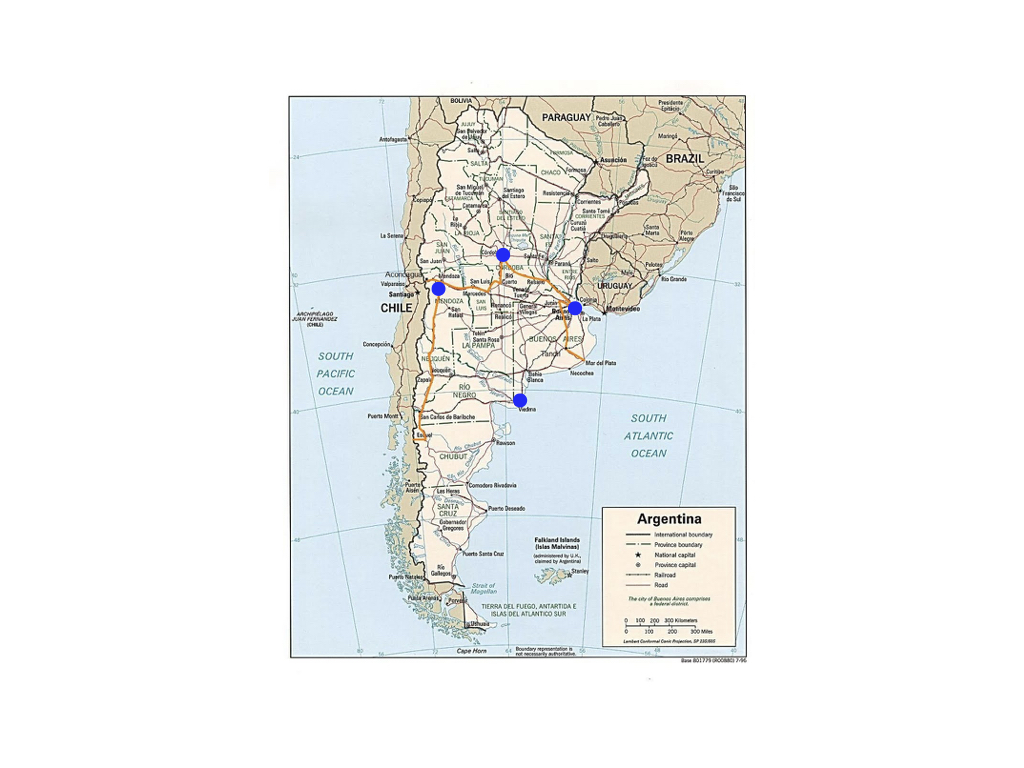
Cartes des formations à l’étranger (cadre AEDRES) 
Depuis 2015, l’utilisation des outils et méthodes d’édition structurée XML-TEI est recommandée par l’INSHS pour la production et la diffusion de revues.
[1] Porté, avec le soutien de BSN, par le Pôle Document numérique, sous la responsabilité de Pierre-Yves Buard, et par les Presses universitaires de Caen forts de leur expérience en édition de sources complexes, en liaison avec l’AEDRES. Sur les modèles, principes et méthodes mis en œuvre et leurs incidences sur l’activité éditoriale savante, voir : Pierre-Yves Buard, « Modélisation des sources anciennes et édition numérique », Thèse de doctorat, Université de Caen Basse-Normandie, 2015 (dactyl.). Sur le paysage de l’édition scientifique institutionnelle et sur l’impact du numérique, voir : « L’édition scientifique institutionnelle en France. État des lieux, matière à réflexions, recommandations », rapport (dactyl.) établi pour l’AEDRES par Jean-Michel Henny avec la collaboration de Denise Pierrot et de Dominique Roux (remis au MENSR en 2015).
[2] Il s’agit ici de la mise en œuvre du modèle défini par Robert Darnton, « Le nouvel âge du livre », Le Débat, 105, 1999, p. 176-184.
[3] Pour une présentation de NUMEDIF, Voir Dominique Roux, « Numédif : au service de l’édition numérique », Arabesques, 84, février-mars 2017, p. 14.
[4] C’est-à-dire l’utilisation d’une même granularité de description des éléments textuels et des formes éditoriales au moyen du vocabulaire de la TEI.
[5] Et pour toute (re)mise en forme en flux : XHTML, Revues.org, OpenEdition Books, Cairn (modèle dérivé d’Érudit), ePub 2 et 3… ou en page : InDesign, PDF et bientôt LATEX, JATS… entre autres.
[6] Pour reprendre une expression utilisée par Marin Dacos (Blogo Numericus, « C’est le chuchotement des livres qui se parlent… », 22/10/2008 ; http://bn.hypotheses.org/167).
[7] Lou Burnard, What is the Text Encoding Initiative?, Marseille, OpenEdition Press (Encyclopédie numérique), 2014 (http://books.openedition.org/oep/1237).